 补充
补充
# 一、 C# 三种集合的典型应用场景及 **Contains** 方法性能对比
在 C# 开发中,选择合适的集合类型取决于是否需要线程安全、元素的唯一性、是否有序以及读写操作的频率。
**List<T>**(列表)
- 核心特征:
- 有序:元素按照添加顺序存储,支持通过索引(Index)直接访问(
**list[0]**)。 - 允许重复:可以存储相同的元素。
- 非线程安全:在多线程环境下同时读写需要手动加锁。
- 有序:元素按照添加顺序存储,支持通过索引(Index)直接访问(
- 适用场景:
- 顺序存储:当你需要保持元素的添加顺序,或者需要通过索引快速访问特定位置的元素时。
- 小规模数据集合:数据量较小(如几百个元素以内),且不需要频繁进行查找操作。
- 允许重复数据:例如记录用户的点击历史、日志流水等。
- 单线程环境:或者在多线程环境下只读不写。
**HashSet<T>**(哈希集)
- 核心特征:
- 无序:内部不保证元素的顺序(虽然在某些实现下看似有序,但不能依赖)。
- 唯一性:自动去重,不能存储重复元素。
- 查找极快:基于哈希表实现,查找速度非常快。
- 非线程安全:多线程并发读写需手动加锁。
- 适用场景:
- 去重:当你有一组数据,需要快速去除重复项时(例如:统计网站的独立访客 IP)。
- 高频查找(Contains):当你需要频繁判断“某元素是否存在于集合中”时,
**HashSet<T>**是最佳选择。 - 集合运算:需要进行数学集合运算,如求交集(
**IntersectWith**)、并集(**UnionWith**)、差集(**ExceptWith**)等场景。
**ConcurrentBag<T>**(并发包)
- 核心特征:
- 线程安全:专为多线程并发设计,读写无需手动加锁。
- 无序:不保证元素的顺序。
- 允许重复:可以存储重复元素。
- 线程本地缓存优化:它的内部实现利用了线程本地存储(Thread-Local Storage),如果一个线程“自己生产、自己消费”,速度非常快;但如果“线程 A 生产,线程 B 消费”,性能会下降(涉及到偷取算法)。
- 适用场景:
- 多线程并发添加/读取:例如多个线程同时采集数据并汇总到一个集合中。
- 生产者-消费者模型(弱顺序要求):多个线程生产任务,多个线程消费任务,且不关心任务的处理顺序。
- 对象池(Object Pool):虽然现在有专门的
**ObjectPool<T>**,但在早期或某些简单场景下,**ConcurrentBag**常被用来实现对象池,因为存取速度在同线程下很快。
# **List<T>** 与 **HashSet<T>** 的 **Contains** 性能对比
- 结论:
**HashSet<T>**** 的**Contains**方法效率远高于**List<T>**,尤其是在数据量较大时。**1. 为什么**HashSet<T>**更快?
- 算法复杂度:
**HashSet<T>**** ****(O(1))**:哈希集内部维护了一个哈希表。当你调用**Contains(item)**时,它会直接计算**item**的哈希值(HashCode),直接定位到内存中的具体位置。无论集合里有 10 个还是 100 万个元素,查找时间几乎是一样的(平均情况)。**List<T>**** ****(O(n))**:列表是基于数组实现的。当你调用**Contains(item)**时,它必须从第一个元素开始,逐个遍历并比较(线性查找),直到找到目标元素或者遍历完整个列表。如果集合有 n 个元素,最坏情况下需要比较 n 次。
- . 性能差异有多大?
- 数据量小(< 10 个):差异微乎其微,甚至
**List<T>**可能因为内存局部性更好而略快,但在人眼感知上无区别。 - 数据量大(> 1000 个):
**HashSet**秒杀**List**。例如查找 1 万个元素,**List**可能需要比较 5000 次(平均),而**HashSet**只需要计算 1 次哈希。
- . 什么时候用
**List.Contains**?
虽然 **HashSet** 快,但如果你的列表很短(比如只有 5 个配置项),为了这点性能去转成 **HashSet** 反而增加了构建哈希表的开销(构建是 O(n) 的)。所以,只有在高频查找且数据量较大的场景下,才强烈建议使用 **HashSet**。
| 特性 | List | HashSet | ConcurrentBag |
|---|---|---|---|
| 有序性 | 有序 (索引访问) | 无序 | 无序 |
| 唯一性 | 允许重复 | 不允许重复 | 允许重复 |
| 线程安全 | 否 | 否 | 是 (并发安全) |
| 查找速度 (Contains) | 慢 O(n) | 极快 O(1) | 较慢 (需遍历) |
| 最佳用途 | 顺序存储、索引访问 | 去重、频繁查找 | 多线程并发读写 |
# 二、try-catch-finally 考察
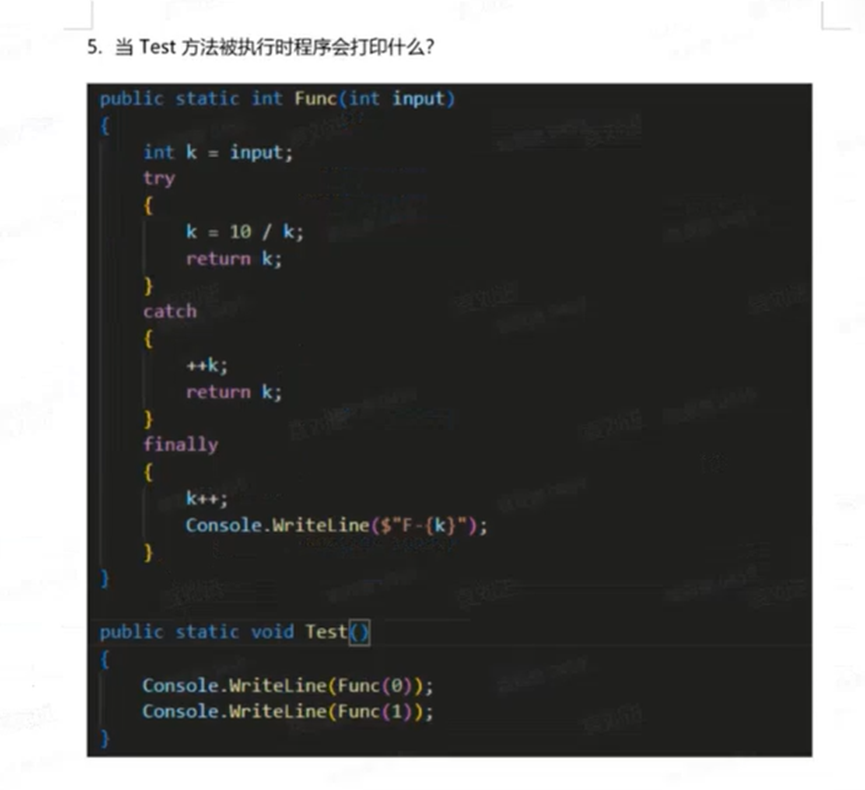
当 Test 方法被执行时,程序会打印以下内容:
F-2
1
F-11
10
2
3
4
# 详细解析
这段代码考察了 C# 中 try-catch-finally 的执行顺序以及 值类型 在 return 和 finally 中的行为细节。
# **第一步:执行 **Func(0)
- 传入参数:
input为 0,初始化int k = 0。 - 执行
try块:k = 10 / k即10 / 0。- 触发异常:抛出
DivideByZeroException,程序跳转到catch块。
- 执行
catch块:++k:k从 0 变为 1。return k:此时准备返回的值是 1。注意:对于值类型(如int),C# 会将此时的返回值(1)暂存起来,准备在finally执行完后返回。
- 执行
finally块:k++:k从 1 变为 2。Console.WriteLine($"F-{k}"):打印 "F-2"。
- 方法返回:
- 方法返回之前暂存的值 1(注意:
finally里对局部变量k的修改不会影响已经暂存的返回值)。 - 回到
Test方法,Console.WriteLine打印返回值 "1"。
- 方法返回之前暂存的值 1(注意:
# **第二步:执行 **Func(1)
- 传入参数:
input为 1,初始化int k = 1。 - 执行
try块:k = 10 / k即10 / 1,k变为 10。return k:此时准备返回的值是 10。同样,这个值被暂存。
- 执行
catch块:- 未发生异常,跳过。
- 执行
finally块:k++:k从 10 变为 11。Console.WriteLine($"F-{k}"):打印 "F-11"。
- 方法返回:
- 方法返回之前暂存的值 10。
- 回到
Test方法,Console.WriteLine打印返回值 "10"。
# 核心知识点总结
- 执行顺序:
return语句会先计算返回值,然后执行finally块,最后才真正退出方法。 - 值类型陷阱:对于值类型变量(如
int),return语句会将要返回的值复制并保存。如果在finally块中修改了该局部变量,不会改变已经保存好的返回值。所以尽管finally里k变成了 2 和 11,但返回值依然是catch或try块里当时的值(1 和 10)。
# 三、值类型与引用类型
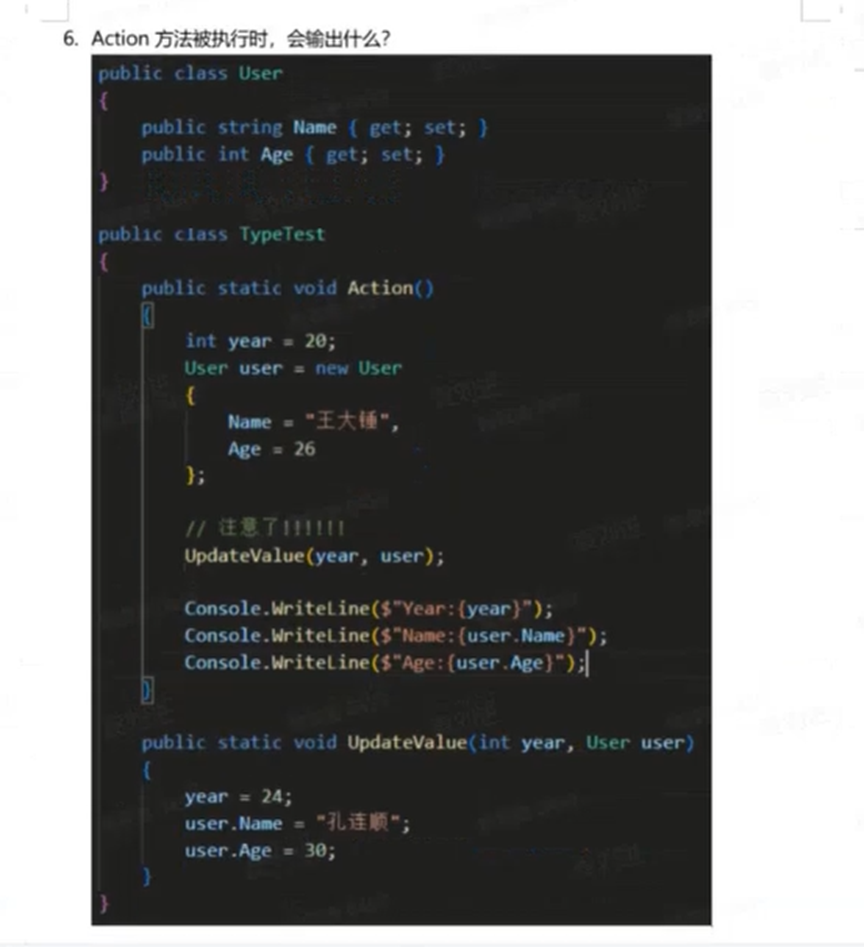 当
当 Action 方法被执行时,程序会输出:
Year:20
Name:孔连顺
Age:30
2
3
# 详细解析
这段代码主要考察 C# 中 值类型(如 int)和 引用类型(如 class)在作为方法参数传递时的行为区别。
# 1. 变量初始化
int year = 20;:定义了一个值类型变量。User user = new User { Name = "王大锤", Age = 26 };:定义了一个引用类型对象。此时user变量存储的是对象在内存堆(Heap)中的地址。
# **2. 调用 **UpdateValue(year, user)
- 参数
year(值类型):- C# 默认按值传递(Pass by Value)。
- 调用方法时,将
year的值(20)复制了一份传给了UpdateValue方法中的参数year。 - 在
UpdateValue内部执行year = 24;时,修改的是副本的值。 - 结果:外部原始的
year变量不受影响,仍然是 20。
- 参数
user(引用类型):- C# 默认按值传递,但对于引用类型,传递的是引用的值(即对象的内存地址)。
- 调用方法时,将
user变量存储的地址复制了一份传给了UpdateValue方法中的参数user。 - 此时,外部的
user和方法内的user都指向堆内存中的同一个对象实例。 - 在
UpdateValue内部执行:user.Name = "孔连顺";user.Age = 30;
- 这些操作是通过地址找到那个唯一的对象并修改其属性。
- 结果:外部的
user变量再次访问时,看到的是已经被修改后的对象。
# 3. 输出结果
Console.WriteLine($"Year:{year}");-> 打印原始值 20。Console.WriteLine($"Name:{user.Name}");-> 打印修改后的属性 孔连顺。Console.WriteLine($"Age:{user.Age}");-> 打印修改后的属性 30。
# 四、线程异步问题
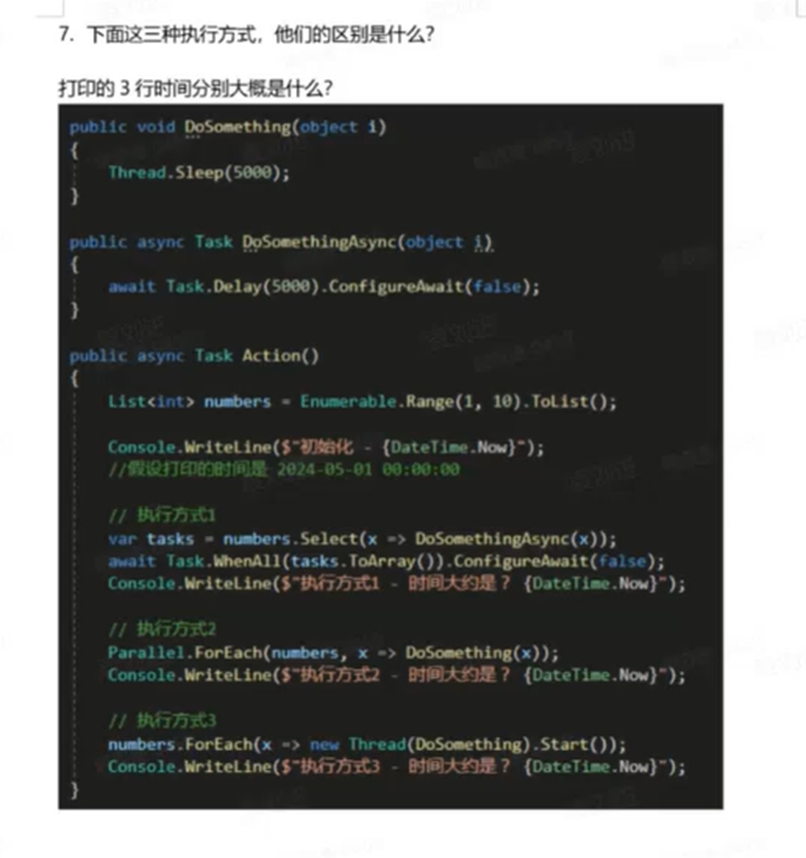
我猜你是想问“请解答”或者“请详解”,输入法可能误触了(“清洁剂”😂)。下面针对这道关于 C# 并发编程的经典面试题进行详细解答。
假设初始时间为 2024-05-01 00:00:00,任务列表 numbers 包含 10 个元素,每个任务耗时 5秒。
# 执行方式 1:基于 Task 的异步并发
- 代码分析:
var tasks = numbers.Select(x => DoSomethingAsync(x));
await Task.WhenAll(tasks.ToArray()).ConfigureAwait(false);
2
1. `DoSomethingAsync` 是一个异步方法,内部使用了 `await Task.Delay(5000)`。
2. `numbers.Select(...)` 会**几乎瞬间**启动 10 个异步任务(Task)。
3. 这 10 个任务是**并发执行**的(非阻塞)。由于 `Task.Delay` 不占用线程池线程(基于定时器),系统可以轻松同时处理这 10 个等待。
4. `Task.WhenAll` 会等待所有任务都完成。
- 耗时预估:
所有任务同时开始,同时等待 5 秒。因此总耗时取决于最慢的那个任务,即 5秒。 - 打印时间:
大约是 2024-05-01 00:00:05。
# 执行方式 2:Parallel.ForEach (并行同步阻塞)
- 代码分析:
Parallel.ForEach(numbers, x => DoSomething(x));
1. `DoSomething` 是同步方法,内部调用 `Thread.Sleep(5000)`,这意味着它会**真实地阻塞线程** 5 秒钟。
2. `Parallel.ForEach` 会利用线程池(ThreadPool)来并发执行任务。
3. **关键点**:默认情况下,线程池的线程数量是有限的,且增长策略(Hill Climbing)较为保守。
* 如果有足够的空闲线程(>=10个),它可能瞬间并发执行完,耗时 **5秒**。
* **但是**,在很多环境(尤其是刚启动时),线程池可能没有一下子提供 10 个线程。它可能先用 4 个或 8 个线程跑(取决于 CPU 核数),剩下的任务得等前面的跑完释放线程。
* 假设它是分两批跑的(比如第一批 8 个,第二批 2 个),那么耗时就是 5 + 5 = **10秒**。
- 耗时预估:
- 理想情况(资源充足):5秒。
- 常见情况(受限于线程池):5秒 ~ 10秒之间(取决于
MinThreads设置和 CPU 核数)。通常面试标准答案会倾向于 5秒(假设并行度足够),但需指出其对线程池的压力。
- 打印时间:
大约是 2024-05-01 00:00:05 (如果并行度足够)。
# 执行方式 3:手动创建线程 (Thread)
- 代码分析:
numbers.ForEach(x => new Thread(DoSomething).Start());
1. 这段代码遍历 10 次,每次都 `new Thread(...).Start()`。这意味着它向操作系统申请了 10 个**专用线程**。
2. 但这行代码有个巨大的陷阱:**它只负责“启动”线程,却没有任何“等待”线程结束的代码(如 **`Join`**)!**
3. 主线程执行完 `ForEach` 循环(启动完线程)后,**立刻**就会执行下一行 `Console.WriteLine`。
4. 此时,那 10 个后台线程可能才刚刚开始睡,或者还没开始睡。
- 耗时预估:
启动 10 个线程只需要几毫秒,几乎瞬间完成。 - 打印时间:
大约是 2024-05-01 00:00:00(或者 00:00:00.0x,即几乎没过时间)。
# 总结与区别
| 方式 | 核心机制 | 是否阻塞线程 | 是否等待完成 | 预估耗时 | 备注 |
|---|---|---|---|---|---|
| 方式 1 | 异步并发 (Task) | 否 (IO密集型推荐) | 是 (await WhenAll) | ~5秒 | 最推荐。高效利用资源,不占用线程池线程进行等待。 |
| 方式 2 | 并行处理 (Parallel) | 是 (阻塞线程池) | 是 (ForEach 会阻塞直到完成) | ~5秒 | 适合 CPU 密集型。在 IO 等待(Sleep)场景下极其浪费线程池资源,可能导致线程饥饿。 |
| 方式 3 | 手动多线程 (Thread) | 是 (专用线程) | 否 (Fire-and-forget) | ~0秒 | Bug 写法。主线程没等待任务结束就打印了。且频繁创建销毁线程开销大,不可控。 |
最终打印时间大概是:
- 方式 1:00:00:05
- 方式 2:00:00:05
- 方式 3:00:00:00 (几乎立即)
# 五、对象映射
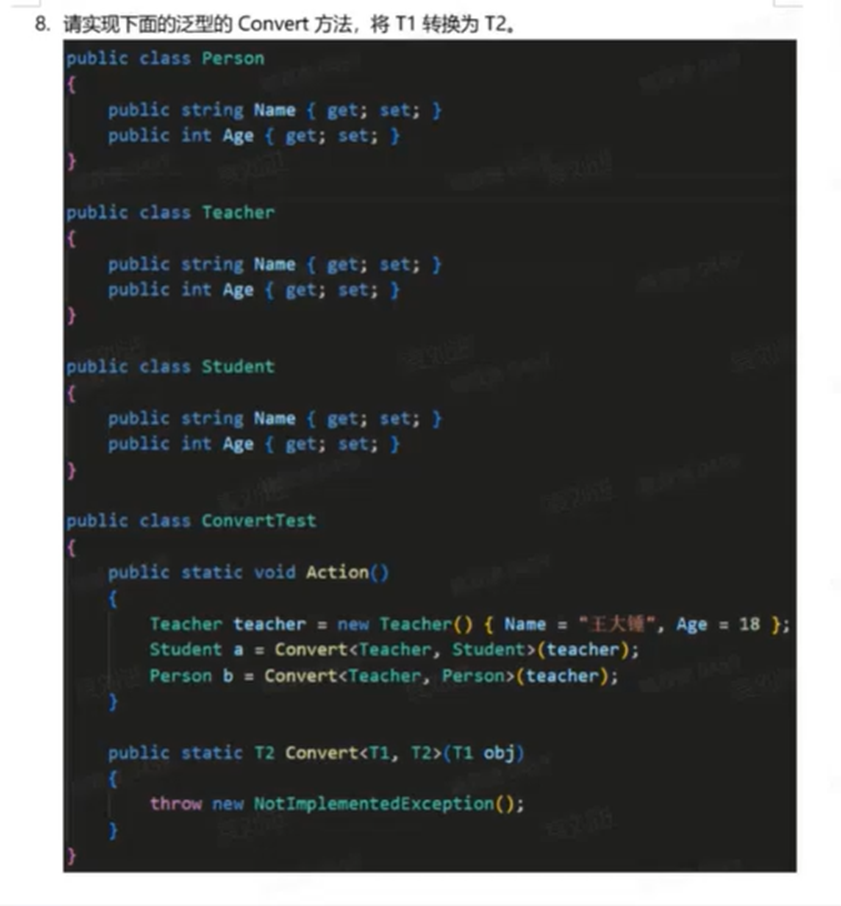 这是一个典型的 对象映射 (Object Mapping) 面试题。由于
这是一个典型的 对象映射 (Object Mapping) 面试题。由于 T1 和 T2 是两个完全不同的类(没有继承关系),但属性名和类型相同,我们需要一种机制把 T1 的属性值“复制”到 T2 中。
在 C# 中,主要有三种实现方式,面试时推荐优先回答 方式一(反射),并补充 方式二(JSON序列化) 作为加分项。
# 方式一:使用反射 (Reflection) - 标准答案
这是最考察 C# 基础功底的写法。原理是通过运行时检查类型的元数据,找到同名的属性并进行赋值。
代码实现:
public static T2 Convert<T1, T2>(T1 obj)
{
// 1. 如果源对象为空,直接返回 T2 的默认值(通常是 null)
if (obj == null)
{
return default(T2);
}
// 2. 使用 Activator 创建 T2 的一个新实例
// 注意:因为方法签名里没有 where T2 : new() 约束,所以不能直接用 new T2()
T2 result = Activator.CreateInstance<T2>();
// 3. 获取 T1 和 T2 的所有属性信息
var t1Type = typeof(T1);
var t2Type = typeof(T2);
// 获取 T1 的属性(只读或读写)
var t1Properties = t1Type.GetProperties();
// 获取 T2 的属性(只写或读写)
var t2Properties = t2Type.GetProperties();
// 4. 遍历目标类型 T2 的所有属性
foreach (var prop2 in t2Properties)
{
// 如果 T2 的属性不可写,跳过
if (!prop2.CanWrite) continue;
// 5. 在 T1 中查找是否存在同名且类型相同的属性
var prop1 = t1Properties.FirstOrDefault(p =>
p.Name == prop2.Name &&
p.PropertyType == prop2.PropertyType &&
p.CanRead // 确保 T1 的属性是可读的
);
// 6. 如果找到了匹配的属性,进行赋值
if (prop1 != null)
{
var value = prop1.GetValue(obj); // 从源对象取值
prop2.SetValue(result, value); // 赋值给目标对象
}
}
return result;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
优点:
- 不依赖任何第三方库。
- 非常通用,只按名称和类型匹配。
缺点:
- 反射性能相对较差(可以通过缓存优化,但在面试代码中不强求)。
# 方式二:使用 JSON 序列化 (Serialize) - 偷懒/实用技巧
在实际项目中,如果不想写复杂的反射代码,或者对象结构比较复杂(包含嵌套对象),我们可以利用“序列化”作为中转。这被称为 Duck Typing(鸭子类型) 的一种实现。
代码实现:
// 需要引用 System.Text.Json 或 Newtonsoft.Json
public static T2 Convert<T1, T2>(T1 obj)
{
if (obj == null) return default(T2);
// 1. 先把 T1 序列化成 JSON 字符串
string json = System.Text.Json.JsonSerializer.Serialize(obj);
// 2. 再把 JSON 字符串反序列化成 T2
return System.Text.Json.JsonSerializer.Deserialize<T2>(json);
}
2
3
4
5
6
7
8
9
10
11
优点:
- 代码极短,逻辑简单。
- 自动处理深拷贝和嵌套对象。
缺点:
- 性能开销比反射更大(涉及字符串分配和解析)。
- 需要引入序列化库。
# 总结
如果是在面试白板上写代码,建议写第一种(反射),因为这体现了你对 C# 类型系统 (Type, PropertyInfo, Activator) 的理解。写完后可以口头提一下:“在生产环境中,为了性能我们通常会使用 AutoMapper 这样的库,或者使用 Expression Tree(表达式树) 预编译来提高性能,或者简单场景下用 JSON 序列化过渡。”
# 六、泛型类的静态成员 (Static Members in Generic Classes) 的行为
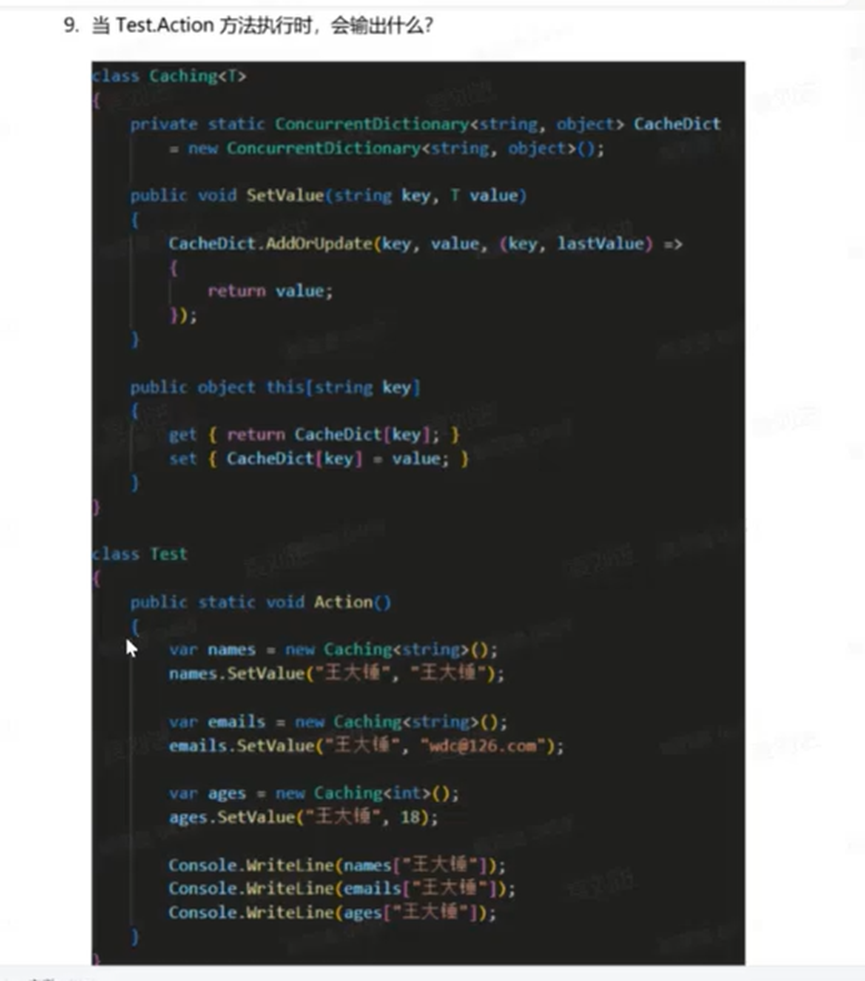
当 Test.Action 方法被执行时,程序会输出:
wdc@126.com
wdc@126.com
18
2
3
# 详细解析
这段代码的核心考点是 泛型类的静态成员 (Static Members in Generic Classes) 的行为。
# 1. 泛型类的静态成员特性
在 C# 中,泛型类的每一个不同的封闭类型(Closed Type),都会生成该类的一个全新版本,并拥有自己独立的一份静态字段。
Caching<string>是一个类型。Caching<int>是另一个完全不同的类型。- 它们不共享静态字段
CacheDict。
# 2. 代码执行流程分析
var names = new Caching<string>();- 实例化了
Caching<string>类型。 - 此时,CLR 为
Caching<string>创建了一个静态字段CacheDict(我们称之为 Dict_String)。 names.SetValue("王大锤", "王大锤");-> 向 Dict_String 中写入键值对:["王大锤"] = "王大锤"。
- 实例化了
var emails = new Caching<string>();- 注意!这里实例化的仍然是
Caching<string>类型。 - 因此,
emails对象访问的静态字段CacheDict依然是上面的 Dict_String。 emails.SetValue("王大锤", "wdc@126.com");-> 这里调用了AddOrUpdate。- 由于 key "王大锤" 在 Dict_String 中已经存在,所以执行更新操作。
- Dict_String 中的值被更新为
"wdc@126.com"。
- 注意!这里实例化的仍然是
var ages = new Caching<int>();- 实例化了
Caching<int>类型。这是一个新的封闭泛型类型。 - CLR 为
Caching<int>创建了一个全新的、独立的静态字段CacheDict(我们称之为 Dict_Int)。 ages.SetValue("王大锤", 18);-> 向 Dict_Int 中写入键值对:["王大锤"] = 18。- 这对之前的 Dict_String 没有任何影响。
- 实例化了
# 3. 输出结果
Console.WriteLine(names["王大锤"]);- 访问
Caching<string>的静态字典 Dict_String。 - 取出的值是最后一次更新的
"wdc@126.com"。
- 访问
Console.WriteLine(emails["王大锤"]);- 访问
Caching<string>的静态字典 Dict_String。 - 取出的值同样是
"wdc@126.com"。
- 访问
Console.WriteLine(ages["王大锤"]);- 访问
Caching<int>的静态字典 Dict_Int。 - 取出的值是
18。
- 访问
# 总结
Caching<string>共享一份静态字典。Caching<int>拥有另一份独立的静态字典。- 同类型的不同实例(
names和emails)修改的是同一个静态数据,发生了数据覆盖。
# 七、LINQ 的 延迟执行 (Deferred Execution) 特性
 这段代码执行后,会输出以下内容:
这段代码执行后,会输出以下内容:
0
1
3
2
3
# 详细解析
这道题考察的是 LINQ 的 延迟执行 (Deferred Execution) 特性。
# 1. 定义 LINQ 查询
int filterCount = 0;
var colors = new List<string>() { "Red", "Yellow", "Blue" }
.Where(x =>
{
filterCount++;
return x.StartsWith("Y");
})
.OrderBy(x => x);
2
3
4
5
6
7
8
- 这行代码仅仅是构建了一个查询表达式(Expression Tree / Iterator State Machine)。
- 此时,
Where和OrderBy内部的委托方法(包括filterCount++)完全没有执行。 colors只是一个等待被遍历的IEnumerable<string>对象。
# 2. 第一次输出
Console.WriteLine(filterCount);
- 由于上面的查询还没开始遍历,
Where里的逻辑还没跑,所以filterCount仍然是初始值 0。 - 输出:0
# 3. 触发执行
Console.WriteLine(colors.Count());
- 调用了
colors.Count()。这是一个立即执行 (Immediate Execution) 的操作,它会强制遍历整个colors集合。 - 为了计算 Count,LINQ 引擎必须让数据通过管道:
- 遍历源数据("Red", "Yellow", "Blue")。
- 对每个元素执行
Where筛选。 - 每执行一次
Where,filterCount就加 1。 - 源数据有 3 个元素,所以
Where委托被执行了 3 次。 filterCount变成了 3。- 筛选结果只有 "Yellow" 一个,所以
Count()返回 1。
- 输出:1
# 4. 第三次输出
Console.WriteLine(filterCount);
- 此时
filterCount已经被累加了 3 次(在执行Count()期间)。 - 输出:3
# 避坑指南
很多初学者会误以为 var colors = ... 这一行执行完后 filterCount 就已经是 3 了。记住:LINQ 查询只有在被迭代(如 foreach, ToList, Count, First 等)时才会真正运行。
# 八、 算法时间复杂度优化 和 LINQ 的正确使用姿势。
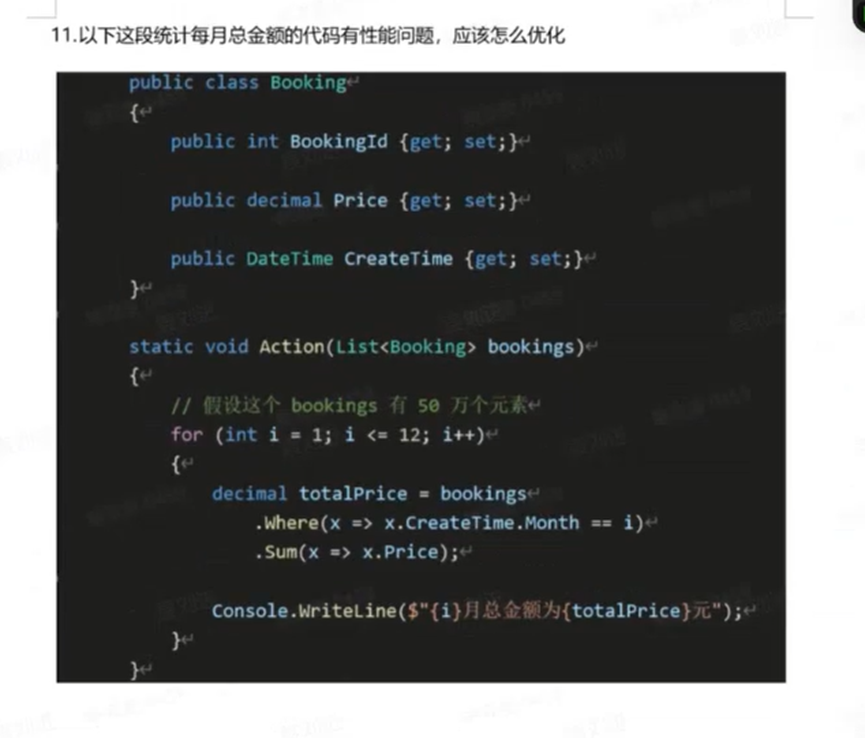
这道题考察的是 算法时间复杂度优化 和 LINQ 的正确使用姿势。
# 问题分析
原代码逻辑如下:
for (int i = 1; i <= 12; i++)
{
decimal totalPrice = bookings
.Where(x => x.CreateTime.Month == i)
.Sum(x => x.Price);
// ... 输出 ...
}
2
3
4
5
6
7
- 重复遍历 (Repeated Traversal):外层循环执行 12 次。每次循环内部,
Where都会遍历整个bookings列表(假设有 50 万数据)。 - 时间复杂度:O(12 * N),即 O(N),但常数系数很大。总共要遍历 50万 * 12 = 600万次元素。
- 性能瓶颈:随着数据量增大,这种“每次只找一个月”的笨办法效率极低。
# 优化方案一:分组 (GroupBy) - 推荐
这是最标准、最符合 LINQ 语义的解法。我们只需要遍历一次数据,按月份分组并求和。
static void ActionOptimized(List<Booking> bookings)
{
// 1. 只遍历一次数据,按月份分组
var monthlyStats = bookings
.GroupBy(x => x.CreateTime.Month)
.Select(g => new
{
Month = g.Key,
TotalPrice = g.Sum(x => x.Price)
})
.OrderBy(x => x.Month) //以此保证输出顺序(可选)
.ToList(); // 立即执行,避免后续可能的重复枚举
// 2. 输出结果(这里只循环最多12次,开销极小)
foreach (var stat in monthlyStats)
{
Console.WriteLine($"{stat.Month}月总金额为{stat.TotalPrice}元");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
- 复杂度:O(N)。只需要扫描一遍列表即可完成分组和聚合。
- 优点:代码清晰,利用了哈希算法(GroupBy 内部)快速归类。
# 优化方案二:一次遍历 + 数组/字典 (One Pass) - 极致性能
如果你追求极致性能,连 LINQ 的委托调用开销和临时对象分配都想省掉,可以用最原始的 foreach。
static void ActionHighPerformance(List<Booking> bookings)
{
// 使用数组作为桶,索引 0 对应 1 月,索引 11 对应 12 月
// 或者直接用 size 13 的数组,忽略索引 0,方便对应月份
decimal[] monthTotals = new decimal[13];
// O(N) 一次遍历
foreach (var booking in bookings)
{
// 假设 CreateTime.Month 只有 1-12
monthTotals[booking.CreateTime.Month] += booking.Price;
}
// 输出结果
for (int i = 1; i <= 12; i++)
{
Console.WriteLine($"{i}月总金额为{monthTotals[i]}元");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
- 复杂度:O(N)。
- 优点:
- 零 GC 压力:除了一个很小的数组,没有创建任何临时对象或闭包。
- CPU 缓存友好:简单的循环和数组访问,对 CPU 分支预测和缓存非常友好。
- 缺点:代码比 LINQ 稍微啰嗦一点点(其实也很简单)。
# 总结
面试时,方案一(GroupBy) 是标准满分答案,因为它展示了你对 LINQ 的熟练掌握。如果能顺口提一下 方案二(数组桶统计),说明你有很强的性能优化意识,是加分项。
# 九、 NET默认的依赖注入里面,服务的生存期(Servicelifetime)可以设为哪几种?通过services.AddDbContext注入的EF Core的DbContext的默认的服务生存期是哪种?如果 DbContext使用单例会不会有问题?
这是一道非常经典的 ASP.NET Core 和 EF Core 面试题,考察的是对依赖注入 (DI) 核心概念的理解。
# 1. .NET 默认的服务生命周期有哪几种?
主要有以下三种:
- Transient (瞬时)
- 特点:每次请求服务时(
GetService),容器都会创建一个全新的实例。 - 适用:轻量级、无状态的服务。
- 特点:每次请求服务时(
- Scoped (范围)
- 特点:在同一个“范围”内(通常指一个 HTTP 请求),多次请求服务会返回同一个实例。当请求结束时,实例会被销毁。
- 适用:数据库上下文 (
DbContext)、用户会话信息等。
- Singleton (单例)
- 特点:在整个应用程序生命周期内,只创建一个实例。所有请求都共享这个实例。
- 适用:缓存服务、配置服务、耗费资源创建的服务。
# 2. EF Core 的 DbContext 默认生命周期是哪种?
- 默认是
Scoped(范围生命周期)。 - 当你调用
services.AddDbContext<MyContext>(...)时,底层默认注册为Scoped。这保证了在一次 HTTP 请求中,所有的数据库操作都复用同一个连接(和同一个事务),并且在请求结束后自动释放数据库连接。
# 3. 如果 DbContext 使用单例 (Singleton) 会不会有问题?
会有严重问题!绝对禁止这样做。
主要原因有三点:
- 非线程安全 (Not Thread-Safe)
DbContext的设计不是线程安全的。- 如果设为单例,那么成千上万个并发的 HTTP 请求会同时使用同一个
DbContext实例。这会导致状态混乱、数据错乱,甚至抛出并发异常(如“在前一个操作完成之前,第二个操作已启动”)。
- 连接不释放 (Connection Leak / Exhaustion)
DbContext通常持有数据库连接。如果是单例,连接可能长期保持打开状态,或者因为异常状态没有重置而导致后续所有请求都失败。
- 内存泄漏 (Memory Leak) - 变更追踪
DbContext内部有一个 Change Tracker (变更追踪器),它会记录所有查询出来的实体状态。- 如果是单例,这个追踪器里的实体会越积越多,永远不被释放,导致服务器内存逐渐耗尽(OOM)。
# 补充面试加分项
- 问:那如果我非要在 Singleton 服务(如后台定时任务)里用 DbContext 怎么办?
- 答:注入
IServiceScopeFactory,手动创建 Scope。
public class MyBackgroundService : BackgroundService
{
private readonly IServiceScopeFactory _scopeFactory;
// 构造函数注入工厂
public MyBackgroundService(IServiceScopeFactory scopeFactory)
{
_scopeFactory = scopeFactory;
}
protected override async Task ExecuteAsync(CancellationToken stoppingToken)
{
// 手动创建 Scope
using (var scope = _scopeFactory.CreateScope())
{
// 从 Scope 中解析 DbContext (此时是 Scoped 的)
var dbContext = scope.ServiceProvider.GetRequiredService<MyDbContext>();
// Do something...
} // Scope 结束,DbContext 被正确释放
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 十、抽象类和接口区别
# 1.1 它们之间的区别是什么?
| 对比维度 | 抽象类 (Abstract Class) | 接口 (Interface) |
|---|---|---|
| 继承数量 | 一个类只能继承一个抽象类 | 一个类可以实现多个接口 |
| 成员类型 | 可以有字段、属性、构造函数、方法(抽象/具体都可以) | 传统上只能定义方法签名、属性签名(C# 8+ 支持默认实现) |
| 访问修饰符 | 成员可以有各种访问级别(public/protected/private) | 成员默认是 public |
| 实现要求 | 子类可以选择性重写虚方法,必须实现抽象方法 | 实现类必须实现所有接口成员(除非有默认实现) |
| 是否有状态 | 可以有字段,维护状态 | 不能有字段(无状态) |
| 构造函数 | 可以有构造函数 | 不能有构造函数 |
核心差异:抽象类强调"is-a"关系(继承体系),接口强调"can-do"能力(契约)。[10][11][12]
# 1.2 你通常会在什么场景下会使用抽象类,什么场景会使用接口?
使用抽象类的场景:
- 需要共享代码/状态:当多个相关类需要复用相同的字段或方法实现时(如所有动物都有
Age字段和Eat()方法)。 - 强类型继承关系:构建清晰的继承树(如
Shape->Circle,Rectangle)。 - 模板方法模式:定义算法骨架,让子类实现细节步骤。
- 版本演进:可以在基类添加新的具体方法,而不破坏现有子类(向后兼容性更好)。[12][13]
使用接口的场景:
- 多态能力赋予:给不相关的类赋予同样的能力(如
IDisposable,IComparable),实现"鸭子类型"。 - 解耦与依赖注入:面向接口编程,方便单元测试(Mock)和替换实现(如
ILogger可以换成文件日志、数据库日志、控制台日志)。 - 多实现需求:一个类需要实现多种行为(如
class FileStream : IDisposable, IAsyncDisposable, IStream)。 - 跨层级协作:不同模块通过接口契约通信,避免紧耦合。[11][10]
# 十一、委托与事件 / Action 与 Func
# 委托与事件有什么区别?
| 特性 | 委托 (Delegate) | 事件 (Event) |
|---|---|---|
| 本质 | 方法的引用/函数指针 | 对委托的封装 |
| 外部访问权限 | 可以被外部直接调用、赋值、置空 | 只能 += 订阅或 -= 取消订阅 |
| 触发权限 | 任何持有委托的代码都可以调用 | 只能由声明类内部触发 |
| 安全性 | 容易被外部误操作(如置空、覆盖) | 更安全,封装了发布者的控制权 |
核心区别:事件是带有访问限制的委托,防止外部代码"越权"调用或破坏订阅列表。它符合"发布-订阅"模式的封装原则。[14]
示例对比:
// 委托:外部可以直接调用和赋值
public Action OnClick;
// 风险:外部可以写 OnClick = null; 或直接 OnClick.Invoke();
// 事件:外部只能订阅
public event Action OnClick;
// 安全:外部只能 OnClick += Handler; 不能直接调用或置空
2
3
4
5
6
7
# Action<T1,T2> 与 Func<T1,T2> 有什么区别?
| 类型 | 返回值 | 典型用途 |
|---|---|---|
| Action<T1, T2> | 无返回值 (void) | 执行操作、修改状态、打印日志等副作用操作 |
| Func<T1, T2> | 有返回值 (T2 是返回类型) | 计算结果、转换数据、查询信息 |
记忆口诀:
Action= 做事情(Action 动作)Func= 求结果(Function 函数)[15][16]
示例:
Action<string> print = (msg) => Console.WriteLine(msg); // 无返回值
Func<int, int, int> add = (a, b) => a + b; // 返回 int
2
# 十二、List / HashSet / ConcurrentBag 场景与性能
# 使用场景
| 集合类型 | 核心特征 | 适用场景 |
|---|---|---|
| List | 有序、可重复、支持索引访问 | 顺序存储、需要按索引访问、数据量小或查找不频繁 |
| HashSet | 无序、自动去重、查找极快 | 去重、高频判断元素是否存在、集合运算(交并差) |
| ConcurrentBag | 线程安全、无序、可重复 | 多线程并发添加/取出数据(生产者-消费者模式) |
# Contains 方法哪个更高效?为什么?
答案:HashSet<T>.Contains** 远高于 List<T>.Contains。**
原因:算法复杂度差异
- HashSet:基于哈希表实现。调用
Contains时,先计算元素的哈希值,直接定位到桶(Bucket),平均时间复杂度 O(1)。 - List:基于数组实现。调用
Contains时,从头到尾逐个比较(线性查找),时间复杂度 O(n)。[17][18]
性能差异示例:
- 数据量 10 个:差异可忽略。
- 数据量 10,000 个:
List平均比较 5,000 次,HashSet仍然只需计算 1 次哈希。 - 数据量 1,000,000 个:
List崩溃级慢,HashSet毫秒级返回。
# 十三、 Task.Delay vs Thread.Sleep
| 特性 | Thread.Sleep | Task.Delay |
|---|---|---|
| 执行方式 | 同步阻塞 | 异步等待 |
| 线程占用 | 阻塞当前线程,线程不能干其他事 | 不阻塞线程,线程可以被释放去处理其他请求 |
| 适用场景 | 控制台程序、测试代码、需要"卡住"的场景 | Web API、高并发、IO 密集型操作 |
| 性能影响 | 浪费线程资源,高并发下会导致线程池饥饿 | 高效利用线程池,支持海量并发 |
| 使用方式 | Thread.Sleep(1000); | await Task.Delay(1000); |
核心区别:
Thread.Sleep:线程真的在"睡觉",不干活也不让别人用。Task.Delay:线程说"我去忙别的,1秒后提醒我继续",基于定时器实现。[19][20]
什么时候用哪个?
- 需要阻塞当前流程(如控制台倒计时、单线程同步逻辑):用
Sleep。 - 在 async 方法里需要延迟(如重试、限流、动画):用
await Task.Delay。[20]
好的,这份列表非常长,看起来是你正在面对或准备面对的一场非常全面且硬核的高级面试。
为了帮你高效消化,我将这些题目分为了 “基础必杀”、“并发与多线程”、“数据与性能优化”、“架构与设计” 四大板块,并剔除了我们今天已经详细解答过的问题(如 List/HashSet 区别、Task.Delay、泛型转换、抽象类接口等),重点攻克剩下的盲区与深水区。
# 🟢 板块一:基础必杀与语言特性(查漏补缺)
这里有一些你列表里提到但我们还没讲透的基础题。
# Q1: C# 虚函数 (Virtual) 的机制?
- 面试官想听:多态、动态绑定、vtable(虚方法表)。
- 解答:
virtual允许子类重写(override)父类方法。- 原理:编译器会在类中生成一个 vtable(虚方法表),里面存储了该类所有虚方法的内存地址。调用虚方法时,程序运行时会去查这张表,找到真正应该调用的那个(是父类的还是子类的),这叫动态分派。
# Q2: 用不同方式写一个构造函数?(考语法广度)
- 解答:
- 实例构造函数:
public MyClass() { ... } - 静态构造函数:
static MyClass() { ... }(用于初始化静态数据,类加载时自动运行一次)。 - 私有构造函数:
private MyClass() { ... }(防止外部实例化,用于单例或静态工具类)。 - 主构造函数 (C# 12+):
public class User(string name) { ... }(参数直接跟在类名后面)。
- 实例构造函数:
# Q3: 静态 (Static) vs 堆栈 (Heap/Stack)
- 解答:
- 静态数据:存在 High Frequency Heap (高频堆) 或特殊的静态存储区,生命周期贯穿 App 整个运行期,不会被 GC 回收(除非卸载 AppDomain)。
- 栈 (Stack):存值类型、方法参数、引用类型的地址。快,自动弹出。
- 堆 (Heap):存引用类型对象。慢,需 GC 回收。
# Q4: ConfigureAwait(false) 有什么作用?
- 解答:
- 作用:告诉
await后的代码不需要强制回到原来的“上下文”(Context,比如 UI 线程或 ASP.NET 请求上下文)。 - 好处:1. 性能稍微好点(少一次线程切换);2. 防止死锁(特别是在 WinForm/WPF 等有同步上下文的环境里)。
- 场景:写通用类库(Library)代码时,强烈建议都加上
.ConfigureAwait(false)。
- 作用:告诉
# 🟡 板块二:并发、多线程与异步
这是你列表里重灾区,题目非常多。
# Q5: 异步输出顺序(面试常考代码题逻辑)
- 核心逻辑:
await之前的代码:同步执行。await之后的代码:异步执行(被切分成状态机的下一步)。- 示例:
Console.WriteLine("A");
await Task.Delay(100);
Console.WriteLine("B");
2
3
输出 A -> (等100ms) -> B。
- **坑点**:如果题目里混杂了 `Task.Run` 或没有 `await` 的调用,顺序就会变成“不确定”或“立即返回”。
# Q6: 多线程下单例处理(双重检查锁)
- 代码题标准答案:
public class Singleton
{
private static volatile Singleton _instance;
private static readonly object _lock = new object();
private Singleton() {} // 私有构造
public static Singleton Instance
{
get
{
if (_instance == null) // 第一重检查
{
lock (_lock)
{
if (_instance == null) // 第二重检查
{
_instance = new Singleton();
}
}
}
return _instance;
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
- **Lazy**** 写法 (更推荐)**:`private static readonly Lazy<Singleton> _lazy = new Lazy<Singleton>(() => new Singleton());`
# Q7: 判断主线程是否堵塞?
- 解答:
- 在 UI 程序里,如果界面卡死就是堵塞。
- 在代码层面,可以通过检测心跳或者看 WatchDog。
- 面试技巧:如果你在一个
Task.Run里写个死循环,主线程不会堵塞;但如果你在主线程直接Thread.Sleep或计算大循环,就会堵塞。
# 🟠 板块三:数据、数据库与性能优化
# Q8: 6.2万 / 10万条数据插入优化(SQL Server)
- 解答:
- 最快:SqlBulkCopy(C# 特有神器,秒级插入百万条)。
- 次选:Dapper Plus / EF Core Bulk Extensions(底层也是 BulkCopy)。
- 最慢:循环
foreach+Insert(千万别说这个)。 - SQL 层面:暂时关闭索引、约束,插完再重建(大数据量导入技巧)。
# Q9: 聚集索引 vs 非聚集索引
- 解答:
- 聚集索引 (Clustered):物理排序,数据就存在索引叶子节点上。一张表只能有 1 个(通常是主键)。找数据最快。
- 非聚集索引 (Non-Clustered):逻辑排序,叶子节点存的是“指针”或“主键值”。一张表可以有多个。
- 回表:如果非聚集索引没覆盖查询字段,还得回聚集索引再查一次。
# Q10: 很多数据怎么匹配?例如 2 个 List 查相同部分
- 解答:
- 笨办法:双重
for循环(复杂度 O(N*M)),数据量大直接卡死。 - 好办法:
list1.Intersect(list2)(LINQ 交集)。 - 底层优化原理:把其中一个 List 转成 HashSet(O(1) 查找),然后遍历另一个 List 去 HashSet 里查。整体复杂度降为 O(N+M)。
- 笨办法:双重
# Q11: HashSet 底层实现原理
- 解答:
- 内部维护一个 Bucket 数组 (桶)。
- 存入时:计算
HashCode % BucketLength,放入对应桶。 - 冲突时:如果桶里有数据了(哈希冲突),使用链表法(Entry 链)或者开放寻址法解决。
- 查找时:直接算 HashCode 定位桶,速度极快。
# 基础概念与语言特性模块
# 第一题:值类型与引用类型的本质区别
面试官: "请解释一下C#中值类型和引用类型的区别,这对我们的日常开发有什么影响?"
候选人答案: 这是C#中最基础但非常重要的概念[12 (opens new window)]。简单来说,值类型存储在栈上,引用类型存储在堆上。当我赋值一个值类型变量给另一个变量时,实际上是复制了整个值;但如果赋值一个引用类型,只是复制了指向堆中对象的地址。
比如说,我有一个整数变量 int a = 5 和 int b = a,此时 a 和 b 是完全独立的两个数据,修改 b 不会影响 a。但如果有一个类 User,我做了 User user1 = new User() 和 User user2 = user1,那么 user1 和 user2 指向内存中的同一个对象,修改 user2 的属性同时也会改变 user1 的属性。
这对我们的开发有很大影响。在性能优化时,频繁的装箱和拆箱操作(将值类型转换为引用类型或反之)会产生额外的内存开销。所以在写性能关键代码时,我会尽量避免不必要的装箱操作。
# 第二题:栈与堆的内存分配机制
面试官: "你能详细解释一下栈和堆分别在什么情况下分配内存吗?"
候选人答案: 这涉及到内存的两种分配方式。栈是一种后进先出(LIFO)的数据结构,它的分配和释放都很快,因为只需要移动栈指针。每当进入一个方法,局部变量就被推入栈;当方法返回时,这些变量自动弹出并释放。栈的空间虽然有限,但访问速度非常快。
堆则不同,它用来存储对象和数组。堆的分配需要通过垃圾回收器管理,这涉及到更复杂的内存管理逻辑。当我们创建一个对象时,实际上是在堆上分配空间,然后返回一个引用。堆上的对象会在没有被引用时由垃圾回收器清理。
举个实际的例子:
public class MemoryExample
{
public void TestMethod()
{
int stackVar = 10; // 在栈上分配
User heapVar = new User(); // 在堆上分配对象,在栈上分配引用
// stackVar 存在栈中,heapVar引用存在栈中,User对象存在堆中
}
// 方法结束后,stackVar和heapVar引用都被释放(从栈弹出)
// 但User对象还在堆中,等待垃圾回收
}
2
3
4
5
6
7
8
9
10
11
# 第三题:静态变量、堆栈变量的区别
面试官: "请说明一下静态变量、成员变量和局部变量分别存储在哪里?"
候选人答案: 这三种变量的存储位置完全不同[12 (opens new window)]。
首先,静态变量存储在元数据区(在.NET Framework中是方法区,在.NET Core中是更复杂的地方)。静态变量在类型加载时就初始化,整个应用程序生命周期内只存在一份副本。所有访问这个静态变量的代码都访问的是同一个变量。
成员变量存储在堆上,每个对象实例都有自己的成员变量副本。所以如果我创建了两个User对象,每个对象都有自己的成员变量。
局部变量存储在栈上,只在该方法执行期间存在。一旦方法返回,局部变量就被释放。
public class VariableDemo
{
public static int StaticVar = 10; // 存在元数据区
public int MemberVar = 20; // 存在堆上
public void Method()
{
int localVar = 30; // 存在栈上
}
}
2
3
4
5
6
7
8
9
10
# 第四题:泛型与非泛型的性能差异
面试官: "为什么我们应该使用泛型而不是非泛型的集合?"
候选人答案: 这涉及到装箱和拆箱的性能问题。非泛型集合如ArrayList,存储的是Object类型,当我们存储值类型时必须进行装箱操作,取出时必须拆箱。这些操作都有性能开销,特别是在大数据量的情况下[12 (opens new window)]。
泛型集合如List就不需要进行这些转换,因为它直接存储int类型的值。这样不仅性能更好,还获得了类型安全性——我们可以在编译时就发现类型错误,而不是在运行时。
让我用一个简单的例子说明:
// 非泛型方式 - 需要装箱拆箱
ArrayList list = new ArrayList();
list.Add(5); // 装箱:int转换为object
int value = (int)list; // 拆箱:object转换为int
// 泛型方式 - 无需装箱拆箱
List<int> genericList = new List<int>();
genericList.Add(5); // 直接存储
int value = genericList; // 直接获取
2
3
4
5
6
7
8
9
# 异步编程与多线程核心概念
# 第五题:Task.Delay 和 Thread.Sleep 的区别
面试官: "在异步编程中,什么时候应该用Task.Delay,什么时候应该用Thread.Sleep?它们有什么本质区别?"
候选人答案: 这是异步编程中常见的错误区别源[14 (opens new window)]。这两个方法看起来都是用来延迟的,但实际上机制完全不同。
Thread.Sleep是同步方法,它会阻塞当前线程。线程在睡眠期间无法执行其他任务,线程资源被浪费了。如果我在一个线程池的线程中使用Thread.Sleep,会导致该线程无法为其他任务服务。
Task.Delay是异步方法,它返回一个Task,表示延迟操作。使用Task.Delay时,当前线程不会被阻塞,它可以继续执行其他工作。这是异步编程的核心优势。
// 同步延迟 - 浪费线程
public void SyncDelay()
{
Thread.Sleep(1000); // 当前线程完全阻塞1秒
Console.WriteLine("完成");
}
// 异步延迟 - 不浪费线程
public async Task AsyncDelay()
{
await Task.Delay(1000); // 当前线程不被阻塞
Console.WriteLine("完成");
}
2
3
4
5
6
7
8
9
10
11
12
13
在高并发场景中,使用Task.Delay能显著提高系统的吞吐量,因为线程可以处理更多的任务。所以在异步代码中,总是应该优先使用Task.Delay而不是Thread.Sleep。
# 第六题:ConfigureAwait(false)的作用
面试官: "你能解释一下ConfigureAwait(false)的作用以及为什么某些情况下需要使用它?"
候选人答案: ConfigureAwait(false)是一个性能优化工具,特别是在库代码中[30 (opens new window)]。当我们在异步方法中使用await时,默认情况下,代码会尝试在原始的同步上下文中继续执行。
这对于UI应用非常重要,因为UI元素的修改必须在UI线程上进行。但对于库代码或后台任务,这种上下文切换就是不必要的开销。
// 没有ConfigureAwait
public async Task WithoutConfigureAwait()
{
var data = await httpClient.GetAsync(url);
// 代码会尝试在调用者的上下文中继续
}
// 使用ConfigureAwait
public async Task WithConfigureAwait()
{
var data = await httpClient.GetAsync(url).ConfigureAwait(false);
// 代码可以在任何线程中继续,避免不必要的上下文切换
}
2
3
4
5
6
7
8
9
10
11
12
13
在Windows Forms或WPF应用中,如果异步操作完成后必须返回UI线程但UI线程被阻塞等待结果,就会发生死锁。使用ConfigureAwait(false)可以避免这种情况。所以规则是:在库代码中使用ConfigureAwait(false),在UI代码中保持默认行为。
# 第七题:异步执行顺序问题
面试官: "如果有多个异步操作,如何确保它们按照我们期望的顺序执行?"
候选人答案: 这是异步编程中很容易出错的地方[6 (opens new window)]。异步不等于并行,我们需要明确指定执行顺序。
如果我想顺序执行多个异步操作:
// 错误方式 - 这会并行执行
public async Task WrongWay()
{
await GetUserAsync();
await GetOrderAsync(); // 这两个操作实际上同时运行了
}
// 正确方式 - 顺序执行
public async Task CorrectWay()
{
var user = await GetUserAsync();
var order = await GetOrderAsync(user.Id); // 等待第一个完成再执行第二个
}
// 并行执行
public async Task ParallelWay()
{
var userTask = GetUserAsync();
var orderTask = GetOrderAsync();
await Task.WhenAll(userTask, orderTask); // 显式并行执行
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
关键是要理解await的作用:它会暂停当前方法的执行,直到异步操作完成,然后继续。所以当我们连续写两个await时,实际上是顺序执行的。
# 第八题:Try-Catch-Finally执行顺序
面试官: "请详细说明try-catch-finally的执行顺序,特别是当try块中有return语句时会发生什么?"
候选人答案: 这是一个很容易出错但面试官经常问的问题[13 (opens new window)]。
基本规则是:finally块无论如何都会执行。但具体的执行顺序需要分情况讨论。
情况一:没有异常:
public string Example1()
{
try
{
Console.WriteLine("1. try块");
return "try返回"; // 此时不会立即返回
}
finally
{
Console.WriteLine("2. finally块");
// 输出顺序是:1 -> 2,然后返回"try返回"
}
}
2
3
4
5
6
7
8
9
10
11
12
13
情况二:有异常被catch:
public string Example2()
{
try
{
throw new Exception("错误");
}
catch
{
Console.WriteLine("1. catch块");
return "catch返回";
}
finally
{
Console.WriteLine("2. finally块");
// 输出顺序是:1 -> 2,然后返回"catch返回"
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
很重要的一点是:finally块虽然会执行,但不会改变try或catch块中的返回值。除非finally块中也有return语句,这样的话finally中的return会覆盖之前的返回值[13 (opens new window)]。
public string Example3()
{
try
{
return "try返回";
}
finally
{
return "finally返回"; // 这会覆盖try中的返回值!不推荐这样写
}
// 实际返回:"finally返回"
}
2
3
4
5
6
7
8
9
10
11
12
对于对象引用,虽然返回值本身不变,但如果finally块修改了对象内容,这些修改会被保留,因为引用指向的是同一个对象。
# 集合与数据结构优化
# 第九题:List 和 HashSet 的性能对比
面试官: "你做过数据查询的性能优化吗?为什么我不应该用List来检查元素是否存在?"
候选人答案: 这是一个很好的性能问题[15 (opens new window)][18 (opens new window)]。看似简单的List.Contains操作实际上是个性能瓶颈。
List使用线性搜索,需要遍历整个列表,时间复杂度是O(n)。如果列表有100万条数据,最坏情况下需要检查100万次。
// 坏的做法 - O(n)复杂度
List<int> list = new List<int>();
if (list.Contains(5)) // 需要遍历整个列表
{
// ...
}
// 好的做法 - O(1)复杂度
HashSet<int> set = new HashSet<int>();
if (set.Contains(5)) // 使用哈希计算,直接定位
{
// ...
}
2
3
4
5
6
7
8
9
10
11
12
13
HashSet使用哈希表实现[25 (opens new window)][28 (opens new window)]。它通过哈希函数计算元素的位置,然后直接在对应位置查找,时间复杂度是O(1)。我做过一个实验,当数据量超过1000条时,HashSet的查询速度明显快于List,数据量越大差异越大[18 (opens new window)]。
所以我的规则是:如果需要频繁查询元素是否存在,一定要用HashSet。如果需要保持顺序或频繁按索引访问,才使用List。
# 第十题:两个List查找相同元素
面试官: "如果我有两个很大的List,需要找出它们之间的相同元素,怎么做才能性能最优?"
候选人答案: 这是一个常见的数据处理需求[50 (opens new window)]。简单的方法是两层循环,但那样时间复杂度是O(n²),对于大数据集很糟糕。
更好的方法是使用LINQ的Intersect方法,它内部使用了更优化的算法:
List<int> list1 = new List<int> { 1, 2, 3, 4, 5 };
List<int> list2 = new List<int> { 3, 4, 5, 6, 7 };
// 直接得到相同元素
var commonElements = list1.Intersect(list2); // 结果:3, 4, 5
2
3
4
5
Intersect方法内部使用哈希集合来存储已见元素,避免了重复的比较操作,整体时间复杂度是O(n+m),其中n和m分别是两个列表的大小。
另一种方法是手动使用HashSet:
var set1 = new HashSet<int>(list1);
var set2 = new HashSet<int>(list2);
set1.IntersectWith(set2); // 直接修改set1,保留相同元素
2
3
# 第十一题:List、HashSet和ConcurrentBag的应用场景
面试官: "你能说说List、HashSet和ConcurrentBag分别在什么场景下使用吗?"
候选人答案: 这三个集合类适用于不同的场景[29 (opens new window)][32 (opens new window)]。
List 适合:需要保持元素顺序、频繁按索引访问、在单线程中使用的场景。比如存储用户列表或查询结果。
HashSet 适合:需要快速查询元素是否存在、去重、集合运算(并集、交集、差集)的场景。比如存储用户ID集合,快速判断某个ID是否在集合中。
ConcurrentBag 适合:多线程环境中需要安全添加和移除元素的场景[29 (opens new window)]。它是线程安全的,不需要显式加锁。比如在并行任务中收集结果。
// List - 单线程,需要顺序
List<User> users = new List<User>();
users.Add(user1);
var first = users; // 可以按索引访问
// HashSet - 快速查询
HashSet<int> userIds = new HashSet<int> { 1, 2, 3 };
if (userIds.Contains(1)) // O(1)查询
// ConcurrentBag - 多线程
ConcurrentBag<Result> results = new ConcurrentBag<Result>();
Parallel.For(0, 100, i =>
{
var result = DoWork(i);
results.Add(result); // 线程安全
});
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 第十二题:HashSet的底层实现为什么快
面试官: "HashSet为什么比List快这么多?它的底层是如何实现的?"
候选人答案: 这涉及到哈希表的原理[25 (opens new window)][28 (opens new window)]。HashSet内部使用哈希表,核心机制是通过哈希函数将元素映射到不同的"桶"中。
当我添加一个元素时,HashSet计算它的哈希值,然后根据哈希值确定这个元素应该存放在哪个桶中。当查询时,只需要计算哈希值,然后直接查看对应的桶,而不需要遍历所有元素。
// 简化的HashSet工作原理
public class SimpleHashSet<T>
{
private List<T>[] buckets; // 多个桶
public void Add(T item)
{
int hashCode = item.GetHashCode();
int bucketIndex = hashCode % buckets.Length; // 确定桶的位置
buckets[bucketIndex].Add(item);
}
public bool Contains(T item)
{
int hashCode = item.GetHashCode();
int bucketIndex = hashCode % buckets.Length;
return buckets[bucketIndex].Contains(item); // 只查看该桶
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
我在实际项目中发现,当数据量超过10条时,HashSet就开始显出性能优势,数据量越大优势越明显[18 (opens new window)]。
# 设计模式与架构设计
# 第十三题:单例模式的多线程安全实现
面试官: "请写一个线程安全的单例模式,并解释为什么你这样做。"
候选人答案: 这是设计模式中最基础的问题[7 (opens new window)][10 (opens new window)]。单例模式看似简单,但要在多线程环境下正确实现并不容易。
最简单但错误的实现:
// 错误!非线程安全
public class BadSingleton
{
private static BadSingleton _instance;
public static BadSingleton GetInstance()
{
if (_instance == null) // 两个线程都可能通过这个检查
{
_instance = new BadSingleton();
}
return _instance;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
两个线程可能同时检查到_instance == null,都会创建新实例,违反了单例的初衷。
双检查锁定方式(DCL):
public class DoubleCheckLockSingleton
{
private static volatile DoubleCheckLockSingleton _instance;
private static readonly object _lock = new object();
public static DoubleCheckLockSingleton GetInstance()
{
if (_instance == null) // 第一次检查,避免不必要的锁
{
lock (_lock) // 线程安全的锁
{
if (_instance == null) // 第二次检查
{
_instance = new DoubleCheckLockSingleton();
}
}
}
return _instance;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
这种方式兼顾了性能和安全性,但比较复杂。
最优方式 - 利用.NET的静态初始化:
public class Singleton
{
private static readonly Singleton _instance = new Singleton();
public static Singleton GetInstance()
{
return _instance;
}
private Singleton() // 私有构造函数
{
}
}
2
3
4
5
6
7
8
9
10
11
12
13
这种方式利用了C#编译器和运行时对静态字段的初始化保证了线程安全,而且无需显式的锁。这是我在项目中最常用的方式[7 (opens new window)]。
还有一种现代的方式使用Lazy:
public class LazySingleton
{
private static readonly Lazy<LazySingleton> _instance =
new Lazy<LazySingleton>(() => new LazySingleton());
public static LazySingleton GetInstance()
{
return _instance.Value; // 真正的延迟初始化
}
}
2
3
4
5
6
7
8
9
10
# 第十四题:抽象类与接口的应用场景
面试官: "你什么时候使用抽象类,什么时候使用接口?它们之间有什么区别?"
候选人答案: 这是OOP设计中很重要的问题[22 (opens new window)]。抽象类和接口看起来相似,但设计目的完全不同。
抽象类 表示"是一个"的关系,代表概念上的一类东西。比如Animal是一个抽象类,Dog和Cat是具体实现。抽象类可以包含实现方法、字段和构造函数。
接口 表示"能做什么"的能力,定义行为规范。一个类可以实现多个接口,比如Dog既可以实现IAnimal接口也可以实现IComparable接口。
我的选择标准是:如果多个类有共同的代码需要复用,使用抽象类;如果定义跨不相关类的通用行为规约,使用接口。
// 抽象类 - 共享实现
public abstract class Animal
{
public string Name { get; set; }
public void Sleep() // 共享实现
{
Console.WriteLine($"{Name}在睡觉");
}
public abstract void MakeSound(); // 抽象方法
}
// 接口 - 行为规约
public interface IMovable
{
void Move();
}
public interface IComparable<T>
{
int CompareTo(T other);
}
// 类可以继承抽象类并实现多个接口
public class Dog : Animal, IMovable, IComparable<Dog>
{
public override void MakeSound()
{
Console.WriteLine("汪汪");
}
public void Move()
{
Console.WriteLine("狗在跑");
}
public int CompareTo(Dog other)
{
return this.Name.CompareTo(other.Name);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
在我的项目中,通常是先定义接口作为契约,然后用抽象类提供通用实现,最后具体类继承抽象类并实现接口[22 (opens new window)]。
# 第十五题:委托、事件和Lambda表达式
面试官: "解释一下委托、事件和Lambda表达式之间的关系,并给出实际应用例子。"
候选人答案: 这三个概念构成了C#中函数式编程的基础[20 (opens new window)][21 (opens new window)]。
委托 是类型安全的函数指针,定义了方法的签名。它相当于说"我需要一个接受string参数、返回void的方法"。
public delegate void MyDelegate(string message);
事件 是委托的一种特殊用法,提供了更好的封装。事件只允许在定义它的类内部触发,外部只能订阅或取消订阅。
public class Button
{
public event EventHandler Clicked; // 事件
public void Click()
{
Clicked?.Invoke(this, EventArgs.Empty); // 只有类内部能触发
}
}
2
3
4
5
6
7
8
9
Lambda表达式 是匿名方法的简化语法,让代码更简洁。
// 没有Lambda的方式
button.Clicked += (sender, e) =>
{
Console.WriteLine("按钮被点击");
};
// Action和Func是最常用的委托
Action<string> print = s => Console.WriteLine(s);
Func<int, int, int> add = (a, b) => a + b;
2
3
4
5
6
7
8
9
Action表示无返回值的操作,Func表示有返回值的操作[21 (opens new window)]。在LINQ中,我经常使用Lambda表达式:
var users = userList
.Where(u => u.Age > 18) // Lambda过滤
.OrderBy(u => u.Name) // Lambda排序
.Select(u => u.Name); // Lambda投影
2
3
4
# 第十六题:虚拟函数与多态
面试官: "什么是虚拟函数?它如何实现多态?"
候选人答案: 虚拟函数是实现多态的关键机制[45 (opens new window)]。当一个方法被标记为virtual时,它可以在派生类中被重写,运行时会根据对象的实际类型来调用正确的方法版本。
public class Shape
{
public virtual void Draw()
{
Console.WriteLine("绘制形状");
}
}
public class Circle : Shape
{
public override void Draw()
{
Console.WriteLine("绘制圆形");
}
}
public class Rectangle : Shape
{
public override void Draw()
{
Console.WriteLine("绘制矩形");
}
}
// 多态的威力
Shape shape1 = new Circle();
Shape shape2 = new Rectangle();
shape1.Draw(); // 输出:"绘制圆形"
shape2.Draw(); // 输出:"绘制矩形"
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
关键是,虽然shape1和shape2都声明为Shape类型,但运行时会根据实际对象类型调用相应的Draw方法。这就是多态。
虚拟方法有一定的性能开销,因为涉及到运行时的类型查询,但这个开销通常可以忽略,而且代码的灵活性大大提高。
# LINQ查询优化
# 第十七题:LINQ延迟执行的陷阱
面试官: "请解释什么是LINQ的延迟执行,以及它可能带来什么问题。"
候选人答案: 这是LINQ中最容易出错但也最重要的概念[8 (opens new window)][39 (opens new window)]。LINQ查询不是在定义时立即执行的,而是在实际使用结果时才执行,这叫延迟执行。
// 定义查询
var query = userList.Where(u => u.Age > 18);
// 在这一刻,查询还没有执行!
// 这里才真正执行查询
foreach (var user in query)
{
Console.WriteLine(user.Name);
}
2
3
4
5
6
7
8
9
10
这听起来很合理,但会带来性能问题。如果我多次遍历同一个查询,它会执行多次:
// 问题代码
var query = userList.Where(u => u.Age > 18);
Console.WriteLine(query.Count()); // 执行一次
foreach (var user in query) // 执行第二次
{
Console.WriteLine(user.Name);
}
// 总共执行了两次查询!
2
3
4
5
6
7
8
9
10
解决方案是使用ToList()或ToArray()缓存结果:
// 解决方案
var users = userList.Where(u => u.Age > 18).ToList(); // 执行一次,结果被缓存
Console.WriteLine(users.Count); // 使用缓存
foreach (var user in users) // 使用缓存
{
Console.WriteLine(user.Name);
}
2
3
4
5
6
7
8
但需要注意的是,缓存会占用内存。所以应该根据数据量大小和查询复杂度来判断是否需要缓存[11 (opens new window)]。
# 第十八题:计算每月总金额的性能优化
面试官: "你需要计算过去12个月的总销售额,应该怎么做最高效?"
候选人答案: 这是一个很实际的性能优化问题[51 (opens new window)]。最常见的错误做法是对每个月单独计算一次总和:
// 很慢的方式 - O(n*12)
var monthlyTotals = new Dictionary<int, decimal>();
for (int month = 1; month <= 12; month++)
{
monthlyTotals[month] = salesList
.Where(s => s.Date.Month == month) // 遍历整个列表
.Sum(s => s.Amount);
}
2
3
4
5
6
7
8
这样做,如果有100万条销售记录,整个列表就会被遍历12次,总共遍历1200万次。非常低效。
最优的方案是只遍历一次列表:
// 快速的方式 - O(n)
var monthlyTotals = new Dictionary<int, decimal>();
foreach (var sale in salesList)
{
int month = sale.Date.Month;
if (!monthlyTotals.ContainsKey(month))
{
monthlyTotals[month] = 0;
}
monthlyTotals[month] += sale.Amount;
}
2
3
4
5
6
7
8
9
10
11
或者使用LINQ的GroupBy:
// 使用LINQ - 更简洁
var monthlyTotals = salesList
.GroupBy(s => s.Date.Month)
.ToDictionary(g => g.Key, g => g.Sum(s => s.Amount));
2
3
4
这个优化将算法复杂度从O(n*12)降低到O(n),对于大数据集来说性能提升是巨大的[51 (opens new window)]。
# 数据库与性能优化
# 第十九题:主键与插入性能
面试官: "为什么选择主键的方式会影响数据库的插入性能?"
候选人答案: 这涉及到数据库索引的特性[9 (opens new window)][12 (opens new window)]。不同的主键选择会直接影响插入性能。
使用自增整数作为主键是最优的选择,因为它是有序的。当插入新记录时,数据库可以直接将其添加到B树的末尾。
CREATE TABLE Users (
UserId INT PRIMARY KEY IDENTITY(1,1), -- 最优:自增整数
UserName VARCHAR(100)
);
2
3
4
但如果使用GUID作为主键,就会有问题。GUID是随机的,每条新记录插入时可能会被放在树的任何位置,导致频繁的树平衡操作和页分裂[38 (opens new window)]。
CREATE TABLE Users (
UserId UNIQUEIDENTIFIER PRIMARY KEY DEFAULT NEWID(), -- 不好:随机顺序
UserName VARCHAR(100)
);
2
3
4
如果必须使用GUID,应该使用NEWSEQUENTIALID()生成顺序的GUID[38 (opens new window)]。
# 第二十题:大数据量批量插入优化
面试官: "如果要插入100万条记录到数据库,怎么做最快?"
候选人答案: 这是数据库性能优化的典型问题[55 (opens new window)]。最重要的是减少网络往返和数据库操作次数。
最坏的方法是逐条插入:
// 非常慢 - 100万次数据库往返
foreach (var user in users)
{
using (var cmd = connection.CreateCommand())
{
cmd.CommandText = "INSERT INTO Users VALUES (@name)";
cmd.Parameters.AddWithValue("@name", user.Name);
cmd.ExecuteNonQuery();
}
}
2
3
4
5
6
7
8
9
10
更好的方法是批量插入:
// 快速 - 使用SQL的多行插入
string sql = "INSERT INTO Users VALUES ";
var values = new List<string>();
for (int i = 0; i < users.Count; i++)
{
values.Add($"(@name{i})");
}
sql += string.Join(",", values);
using (var cmd = connection.CreateCommand())
{
cmd.CommandText = sql;
for (int i = 0; i < users.Count; i++)
{
cmd.Parameters.AddWithValue($"@name{i}", users[i].Name);
}
cmd.ExecuteNonQuery();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
最优的方法取决于数据库和驱动。对于SQL Server,可以使用SqlBulkCopy:
// 最快 - 使用专门的批量加载工具
using (var bulkCopy = new SqlBulkCopy(connection))
{
bulkCopy.DestinationTableName = "Users";
bulkCopy.WriteToServer(users);
}
2
3
4
5
6
批量插入的最优行数需要平衡多个因素。一般来说,每次插入1000-10000行是比较好的选择,但具体要根据SQL语句大小和数据库配置来调整[55 (opens new window)]。
# 第二十一题:聚集索引与非聚集索引
面试官: "解释一下聚集索引和非聚集索引,分别在什么场景使用。"
候选人答案: 这是数据库优化的核心知识[38 (opens new window)]。索引的选择直接影响查询性能。
聚集索引 定义了表中数据的物理存储顺序。一个表只能有一个聚集索引,通常是主键。当使用聚集索引查询时,找到索引项就找到了数据。
-- 创建聚集索引(通常是主键)
CREATE CLUSTERED INDEX IX_UserId ON Users(UserId);
2
非聚集索引 不改变数据的物理顺序,只是创建了一个指向数据的指针。一个表可以有多个非聚集索引。
-- 创建非聚集索引
CREATE NONCLUSTERED INDEX IX_UserName ON Users(UserName);
2
选择的原则是[38 (opens new window)]:
- 聚集索引应该建在频繁查询的列,比如用户ID
- 非聚集索引应该建在WHERE条件中常用的列
- 如果查询需要的列都包含在索引中,可以使用覆盖索引避免回表查询
-- 覆盖索引 - 包含所有需要查询的列
CREATE NONCLUSTERED INDEX IX_UserNameEmail
ON Users(UserName) INCLUDE (Email);
2
3
性能优化时,我会用EXPLAIN PLAN查看查询计划,看是否使用了索引[38 (opens new window)]。
# 依赖注入与服务生命周期
# 第二十二题:AddSingleton、AddScoped、AddTransient的区别
面试官: "在.NET依赖注入中,三种服务生命周期有什么区别?分别在什么场景使用?"
候选人答案: 这是.NET Core应用开发的基础知识[31 (opens new window)]。理解服务生命周期对写出高效、正确的应用至关重要。
Singleton 在整个应用生命周期内只创建一次实例。所有请求共享同一个实例。
services.AddSingleton<ILogger, Logger>();
// 适用场景:无状态服务、配置对象、缓存服务
// 注意:如果有状态,多个请求的修改会相互影响
2
3
4
Scoped 在每个请求范围内创建一个新实例。同一个请求内的所有代码共享同一个实例。
services.AddScoped<IUserService, UserService>();
// 适用场景:Entity Framework DbContext、工作单元模式
// DbContext必须是Scoped,保证一个请求一个DbContext
2
3
4
Transient 每次请求都创建一个新实例。没有任何共享。
services.AddTransient<INotificationService, EmailNotificationService>();
// 适用场景:无状态、轻量级的服务
// 过度使用会导致内存问题
2
3
4
// 实际例子
public class UserController
{
private readonly IUserService _userService; // Scoped - 一个请求一个实例
private readonly ILogger _logger; // Singleton - 全局共享
private readonly INotification _notif; // Transient - 每次新建
public UserController(
IUserService userService,
ILogger logger,
INotification notif)
{
_userService = userService;
_logger = logger;
_notif = notif;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 第二十三题:DbContext的生命周期管理问题
面试官: "如果把DbContext配置为Singleton会有什么问题?如果在新线程中使用Scoped的DbContext怎么处理?"
候选人答案: 这是我在项目中遇到过的真实问题[31 (opens new window)][32 (opens new window)]。
DbContext被配置为Singleton是大错误。Entity Framework不是设计用来在多线程环境中共享DbContext的。多个线程同时使用同一个DbContext会导致竞态条件和数据不一致[31 (opens new window)]。
// 错误!千万别这样做
services.AddSingleton<ApplicationDbContext>(); // 错误的生命周期
// 正确的做法
services.AddScoped<ApplicationDbContext>(); // DbContext应该是Scoped
2
3
4
5
当在新线程中使用依赖注入时,Scoped的服务会出现问题。原始HTTP请求完成后,Scoped服务会被释放,新线程此时才尝试使用它会抛异常[32 (opens new window)]。
// 问题场景
public class UserController
{
private readonly IServiceProvider _serviceProvider;
public void ProcessUsers()
{
// 在新线程中使用Scoped的DbContext
Task.Run(() =>
{
var dbContext = _serviceProvider.GetRequiredService<ApplicationDbContext>();
// 这会失败!DbContext已经被释放了
});
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
解决方案是在新线程中创建新的作用域:
// 解决方案
public void ProcessUsers()
{
Task.Run(() =>
{
using (var scope = _serviceProvider.CreateScope())
{
var dbContext = scope.ServiceProvider
.GetRequiredService<ApplicationDbContext>();
// 现在可以正常使用
}
});
}
2
3
4
5
6
7
8
9
10
11
12
13
# 代码输出与逻辑题
# 第二十四题:自增运算符和赋值顺序
面试官: "运行下面代码,变量a、b、c、d、e的值分别是什么?"
int a = 9;
int b = a++;
int c = ++a;
int d = c--;
int e = --d;
2
3
4
5
候选人答案: 这个题目考查的是前缀自增和后缀自增的区别[12 (opens new window)]。
a = 9:初始值b = a++:先赋值,后自增。所以b = 9,然后a变成10c = ++a:先自增,后赋值。a从10变成11,然后c = 11d = c--:先赋值,后自减。d = 11,然后c变成10e = --d:先自减,后赋值。d从11变成10,然后e = 10
最终结果:a = 11, b = 9, c = 11, d = 10, e = 10
规律很简单:前缀运算符先运算再赋值,后缀运算符先赋值再运算[12 (opens new window)]。
# 第二十五题:字符串和数字的比较
面试官: "预测下面代码的输出。"
int x = 5;
string y = "5";
if (x == y)
{
Console.WriteLine("相等");
}
else
{
Console.WriteLine("不相等");
}
2
3
4
5
6
7
8
9
10
候选人答案: 答案是"不相等"。在C#中,int和string进行==比较时不会自动转换[12 (opens new window)]。C#不允许在没有显式转换的情况下比较不同的基本类型。
如果我想比较它们的值,需要显式转换:
int x = 5;
string y = "5";
if (x == int.Parse(y)) // 显式转换
{
Console.WriteLine("相等"); // 这会输出
}
2
3
4
5
6
7
或者反过来转换:
if (x.ToString() == y)
{
Console.WriteLine("相等"); // 这也会输出
}
2
3
4
# 第二十六题:null条件运算符
面试官: "这段代码会输出什么?"
User user = null;
Console.WriteLine(user?.Name);
2
候选人答案: 输出是空行(不会抛异常)。null条件运算符?.是C# 6.0引入的特性。当左边是null时,整个表达式立即返回null,不会尝试访问Name属性[12 (opens new window)]。
这等价于:
string name = user != null ? user.Name : null;
Console.WriteLine(name); // 输出null
2
这个特性大大简化了null检查的代码。以前需要写:
// 旧方式
if (user != null && user.Orders != null && user.Orders.Count > 0)
{
var firstOrder = user.Orders;
}
// 新方式
var firstOrder = user?.Orders?; // 干净得多
2
3
4
5
6
7
8
# 并发和异步编程高级问题
# 第二十七题:Parallel.For和多线程执行顺序
面试官: "在多线程环境中,运行以下代码,输出的顺序是什么?"
for (int i = 1; i <= 4; i++)
{
int temp = i;
Task.Run(async () =>
{
await Task.Delay(temp * 100);
Console.WriteLine(temp);
});
}
2
3
4
5
6
7
8
9
候选人答案: 这个问题考查的是异步编程的理解[3 (opens new window)]。代码的执行顺序通常不确定,但会遵循某些规律。
每个任务都会等待temp * 100毫秒,所以:
- 第1个任务等待100ms
- 第2个任务等待200ms
- 第3个任务等待300ms
- 第4个任务等待400ms
由于延迟时间不同,输出顺序通常是:1 2 3 4(按照延迟时间从短到长)。
但如果我们想确保顺序,需要使用await:
for (int i = 1; i <= 4; i++)
{
int temp = i;
await Task.Delay(temp * 100);
Console.WriteLine(temp);
}
// 输出一定是:1 2 3 4
2
3
4
5
6
7
# 第二十八题:Volatile关键字的作用
面试官: "什么时候需要使用volatile关键字?"
候选人答案: volatile关键字告诉编译器和CPU:这个变量可能在任何时候改变,不要对它进行优化。
在多线程环境中,CPU会缓存变量的值来优化性能。如果一个变量被多个线程修改,一个线程可能看不到其他线程的修改。volatile防止了这种缓存:
private volatile bool _stopFlag = false; // 多个线程可能修改
public void Stop()
{
_stopFlag = true;
}
public void DoWork()
{
while (!_stopFlag) // 每次都从内存读取最新值
{
// 做工作
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
没有volatile,编译器可能会优化代码,把!_stopFlag的检查结果缓存起来,导致Stop()方法无法停止工作。
# 第二十九题:死锁问题
面试官: "如何检测和避免多线程死锁?"
候选人答案: 死锁是多线程编程中最难的问题之一[15 (opens new window)]。死锁发生在两个或多个线程互相等待对方释放资源时。
典型的死锁场景:
private object _lock1 = new object();
private object _lock2 = new object();
public void Thread1Work()
{
lock (_lock1)
{
Thread.Sleep(100); // 让线程2先执行
lock (_lock2) // 等待lock2,但线程2持有它
{
Console.WriteLine("Thread1完成");
}
}
}
public void Thread2Work()
{
lock (_lock2)
{
Thread.Sleep(100); // 让线程1先执行
lock (_lock1) // 等待lock1,但线程1持有它
{
Console.WriteLine("Thread2完成");
}
}
}
// 如果同时执行Thread1Work和Thread2Work,会死锁
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
避免死锁的方式[15 (opens new window)]:
- 按照相同的顺序获取多个锁
- 使用超时的Lock
- 使用ReaderWriterLockSlim等高级同步原语
- 尽量减少锁的范围
// 避免死锁的方式:按照相同顺序获取锁
public void Thread1Work()
{
lock (_lock1)
{
lock (_lock2)
{
// 做工作
}
}
}
public void Thread2Work()
{
lock (_lock1) // 同样先获取lock1
{
lock (_lock2)
{
// 做工作
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# 结论与综合建议
通过以上二十九道题目的详细解析,我们覆盖了C#开发中的核心知识领域。从基础的值类型和引用类型,到高级的异步编程、集合优化、数据库性能、设计模式等,每个领域都是大厂技术面试的常见题目。
关键的学习要点包括:理解内存管理的本质,掌握异步编程的正确用法,选择合适的集合数据结构,正确实现设计模式,优化数据库查询性能,管理依赖注入生命周期,以及处理多线程并发问题。
在面试时,不仅要回答出正确答案,更要能够解释为什么这样做、在什么场景下应用、有什么性能影响。这样才能展现出深厚的技术功底,给面试官留下深刻印象。